Tesseract เป็นซอฟต์แวร์และไลบรารีแปลงภาพข้อความ (ที่คนอ่านเข้าใจ) ให้เป็นข้อความ (ที่คอมพิวเตอร์อ่านเข้าใจ) หรือที่เรียกกันว่า OCR
สาเหตุที่ Tesseract ได้รับความนิยม เพราะมันเป็นซอฟต์แวร์เสรี (free software ไม่ต้องจ่ายเงิน มีซอร์สโค้ดให้ดูและแก้ไขเผยแพร่ต่อได้ และประสิทธิภาพมันก็ดี จะเรียกใช้ตรงๆ ทาง command line ก็ได้ หรือจะเขียนโปรแกรมเชื่อมกับ API มันก็ได้ — ดู wrapper และ GUI อื่นๆ ได้ที่หน้า Add Ons ของโครงการ
ภาพที่จะส่งมา Tesseract ต้องเป็นภาพที่ปรับแต่งมาให้เหมาะกับการอ่านข้อความแล้ว คือหมุนมาค่อนข้างตรง และปรับแสงและสีให้อ่านง่าน พื้นหลังสีขาวหรือสีอ่อน ตัวอักษรสีดำ ใน StackOverflow มีคนอธิบายการใช้ OpenCV ปรับภาพเพื่อ OCR เอาไว้
Tesseract รองรับภาษาไทย (น่าจะตั้งแต่รุ่น 3) ตอนนี้รุ่น 4 กำลังจะออก เพิ่มเอนจินที่ใช้โมเดล Deep Learning แบบ LSTM เข้ามา เท่าที่ทีมพัฒนาทดสอบกันเอง มีข้อผิดพลาดน้อยกว่าเอนจินของรุ่นก่อน
โพสต์นี้จะพูดถึงการทดสอบรุ่น 4.0alpha บน macOS และทดลองเพิ่ม/ลดคำในรายคำศัพท์ที่ตัวเอนจิน LSTM จะเอาไปใช้
ส่วนใครจะใช้รุ่นที่ released แล้ว ติดตั้งด้วยวิธีปกติของแต่ละระบบปฏิบัติการได้นะครับ วิธีตามเอกสาร
ติดตั้งไลบรารีที่จำเป็น
brew install autoconf-archive leptonica icu4c pango
ไลบรารี icu4c (เอาไว้จัดการ Unicode) กับ pango (จัดการการวาดตัวอักษร) ติดตั้งเฉพาะถ้าเราต้องการฝึกโมเดลใหม่
อาจจะมีไลบรารีอื่นที่ต้องใช้เพิ่มเติม ลองอ่านที่ configure มันแจ้ง และติดตั้งตามที่มันบอกครับ
ICU ที่มากับ macOS ไม่มีไฟล์ header มาด้วย ดังนั้นใช้คอมไพล์ไม่ได้ ต้องลงใหม่ครับ
ตั้งค่า environment
ในไฟล์ ~/.bash_profile
export PATH="/usr/local/opt/icu4c/bin:$PATH"
export PATH="/usr/local/opt/icu4c/sbin:$PATH"
export LDFLAGS="-L/usr/local/opt/icu4c/lib"
export CPPFLAGS="-I/usr/local/opt/icu4c/include"
อันนี้ผมใช้ brew ปกติของมันจะเอาไลบรารีและเฮดเดอร์ต่างๆ ไปไว้ที่ไดเรกทอรี /usr/local/opt/ ถ้าใครติดตั้งไว้ที่อื่นก็เปลี่ยนตามนั้นครับ
ดาวน์โหลดโค้ดและเตรียมคอมไพล์
โค้ด Tesseract ตัวล่าสุดอยู่ที่ https://github.com/tesseract-ocr/tesseract ก็ไปโคลนหรือฟอร์กมาได้เลย
จากนั้นในไดเรกทอรีของ tesseract เราก็สร้างไฟล์คอนฟิกเพื่อเตรียมคอมไพล์
./autogen.h
และ
./configure
จากนั้นก็คอมไพล์และติดตั้งตัว tesseract
make
make install
และคอมไพล์และติดตั้งตัวโปรแกรมสำหรับฝึกและแก้ไขรายการคำ
make training
make training-install
ถ้าคอนฟิกไม่ผ่านหรือคอมไพล์ไม่ผ่าน ส่วนใหญ่สาเหตุมาจากการที่ tesseract หาไลบรารีที่มันต้องการไม่เจอ ซึ่งอาจจะเกิดจากการที่เครื่องเรายังไม่มี (ก็ติดตั้งซะ) หรือมีแล้วแต่หาไม่เจอ (ก็ลองตั้งค่า environment ดู)
ใช้งาน Tesseract
การจะใช้งาน Tesseract ได้ ต้องมีไฟล์ข้อมูลภาษาให้มันด้วย ซึ่งดาวน์โหลดได้จาก https://github.com/tesseract-ocr/tessdata_best และ https://github.com/tesseract-ocr/tessdata_fast ตัวแรกจะแม่นกว่า ตัวหลังจะเร็วกว่า
โมเดลภาษาไทยชื่อ tha.traineddata
โมเดลภาษาอังกฤษชื่อ eng.traineddata
ตัวอย่างการเรียกใช้งานจาก command line:
tesseract input.png output --oem 1 -l tha -c preserve_interword_spaces=1 --tessdata-dir ./tessdata_best/
- tesseract — เป็นชื่อโปรแกรมที่เราใช้จาก command line
- input.png — ตรงนี้จะเป็นชื่อภาพอะไรก็ได้ ได้ทั้งฟอร์แมต TIFF, PNG, JPG
- output — ชื่อไฟล์ text ใส่ไปแบบนี้ ไฟล์ที่ออกมาจะใช้ชื่อ output.txt (เติม .txt ให้อัตโนมัติ)
- –oem 1 — เลือก OCR Engine mode เป็น LSTM
- -l tha — เลือกภาษาไทย ถ้าเอกสารเรามีทั้งไทยและอังกฤษ ก็ใช้ -l tha+eng
- -c preserve_interword_spaces=1 — บอกเอนจินว่าไม่ต้องแทรกช่องว่างระหว่างตัวอักษรให้ เนื่องจากภาษาไทยเขียนติดกันโดยไม่มีช่องว่าง ถ้าแทรกมาจะอ่านลำบาก
- –tessdata-dir ./tessdata_best/ — บอกไดเรกทอรีที่เก็บข้อมูลโมเดล
เท่าที่ลองให้อ่านภาพตัวอักษรที่ใช้ฟอนต์ Tahoma กับฟอนต์ Sukhumvit Set ก็อ่านได้แม่นอยู่นะครับ ยกเว้นพวกวรรณยุกต์เล็กๆ บางๆ อย่างไม้เอก บางทีจะหายไป เอนจินมันอาจจะไม่เห็น ตรงนี้ถ้าจะแก้ไขทำได้ด้วยการประมวลผลภาพก่อนส่งเข้า Tesseract เช่นทำให้เส้นหนาขึ้น
แก้ไขไฟล์ wordlist
ไฟล์ tha.traineddata จริงๆ ข้างในมีข้อมูลอยู่หลายประเภท เราสามารถแตกมันออกมาเป็นไฟล์ย่อยๆ ได้
combine_tessdata -u ./tessdata_best/tha.traineddata ./tessdata_TEST/tha.
จะได้ไฟล์ unicharset และไฟล์ dawg (Directed Acyclic Word Graphs) ออกมา ซึ่งจากไฟล์เหล่านี้ เราใช้สร้างรายการคำศัพท์ได้
dawg2wordlist ./tessdata_TEST/tha.lstm-unicharset ./tessdata_TEST/tha.lstm-word-dawg ./tessdata_TEST/tha.lstm-word-list
พอได้รายการคำศัพท์มาแล้ว เราแก้มันได้ด้วย text editor ทั่วไปเลย — 1 บรรทัด 1 คำ
พอแก้ไขเสร็จแล้ว ก็ทำกลับกัน คือแปลงรายการคำศัพท์ให้เป็น unicharset และ dawg
wordlist2dawg ./tessdata_TEST/tha.lstm-word-list ./tessdata_TEST/tha.lstm-word-dawg ./tessdata_TEST/tha.lstm-unicharset
และรวมทั้งหมดเข้าด้วยกันเป็นไฟล์ traineddata เพื่อเอาไปใช้งานกับ tesseract
combine_tessdata ./tessdata_TEST/tha.
เราสามารถลองใช้โมเดลใหม่นี้ได้โดยบอก tesseract ผ่านพารามิเตอร์ –tessdata-dir ให้มาใช้ข้อมูลในไดเรกทอรีนี้
(วิธีการจัดการกับไฟล์คำศัพท์นี้ ขอบคุณ Shreeshrii ที่ช่วยอธิบายอย่างละเอียด)
ผลการทดสอบ
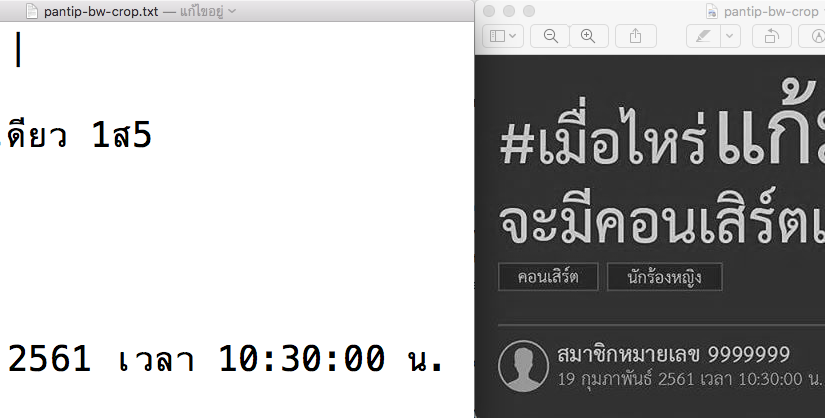
เท่าที่ทดสอบเร็วๆ การ preprocess ประมวลภาพก่อนจะส่งให้ Tesseract มีผลมาก แค่ปรับภาพจากสีเป็นขาวดำ ก็ทำให้อ่านข้อความได้เพิ่มขึ้น และยิ่งเราตัด (crop) ภาพมาเฉพาะส่วนที่มีข้อความ มันก็จะแม่นขึ้นอีก อย่างไรก็ตามการ postprocess อย่างการทำ spellcheck แก้คำผิด ก็ยังจำเป็นอยู่ ถ้าต้องการความแม่นยำที่เพิ่มขึ้นครับ
ด้านล่างเป็นผลทดสอบด้วยโมเดลจาก tessdata_best โดยไม่ได้ปรับแต่งอะไรเพิ่ม



ใครลองเล่นแล้วได้ผลอย่างไรบอกกันได้ครับ
2 responses to “ทดลอง Tesseract 4.0alpha กับภาษาไทย”
สุดยอดดดด
สร้างรายการยังไงหรอครับ พอดีถ้าใช้เป็นบนWindow เนี่ยจะแตกไฟล์นั้นออกยังไงเหรอครับ