-
ทดลอง Tesseract 4.0alpha กับภาษาไทย
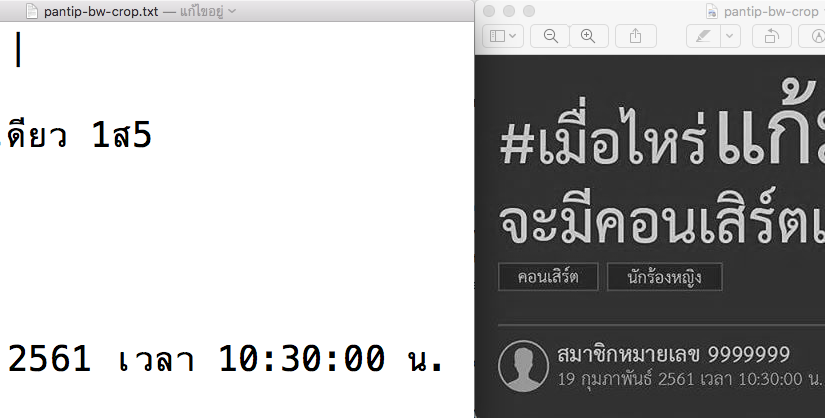
-
Punctual translation with punctuation marks
ความแตกต่างของคำแปลโดย Google Translate ที่เกิดจากการมีและไม่มีเครื่องหมายวรรคตอน วันนี้พบโดยบังเอิญ (2011.02.18): “ถ่ายในห้อง (มีเครื่องหมายคำพูด) → “shot in the room. ถ่ายในห้อง (ไม่มีเครื่องหมายคำพูด) → Taken in the room. นี่อาจจะบอกได้ว่า Google Translate ใช้เครื่องหมายวรรคตอนในการคำนวณสถิติเพื่อใช้ในการแปลด้วย เท่าที่เคยพบ งานทางด้านการประมวลผลภาษาธรรมชาติจำนวนมาก ไม่ค่อยสนใจเครื่องหมายวรรคตอนเท่าไหร่ (เว้นสาขา natural language generation และ discourse analysis) บางทีกรองทิ้งไปเลยก็มี Say, Bilge and Akman, Varol (1997). Current Approaches to Punctuation in Computational Linguistics Jones, Bernard (1996). What’s The Point? A…
-
ช่วงช่วง หลินฮุ่ย เคอิโงะ เสื้อแดง เอ็นจีวี นักศึกษา แพนด้า SEO OCR
OCRopus โอเพ่นซอร์สทูลคิตสำหรับงาน OCR รุ่น 0.4 ออกแล้วครับ น่าจะคอมไพล์อะไรต่าง ๆ ได้ง่ายขึ้นบนแพลตฟอร์มที่ไม่ใช่ GNU/Linux ครับ ดาวน์โหลดได้ทันทีที่เว็บไซต์ OCRopus (โอเพ่นซอร์ส Apache License 2.0) ที่หน้าเว็บ Course: OCRopus สอนการใช้งานและปรับแต่ง OCRopus มีวิธีเขียน Lua และ C++ เพื่อเรียกใช้ OCRopus ด้วย แม้ OCRopus จะรองรับการเพิ่มเติมภาษาใหม่ ๆ เข้าไปได้ แต่ก็ต้องลงแรงหน่อย ตอนนี้ยังใช้ไทยไม่ได้โดยทันที สำหรับคนที่มองหาตัวที่อ่านภาษาไทยได้ และไม่แพงนัก ลองหา ArnThai (อ่านไทย) มาทดสอบดู มีทั้งบนวินโดวส์และลีนุกซ์ (รุ่นบนลีนุกซ์เก่ากว่าหน่อย) ติดต่อเนคเทคได้ ถ้าสนใจนำไปใช้ ที่เคยถาม สามารถตกลงสัญญาอนุญาตได้หลายแบบ สำหรับตัวที่มีประสิทธิภาพดีกว่านั้นและมีความสามารถเพิ่มเติมอื่น ๆ ที่อ่านไทยได้ คือ ABBYY FindReader อ่าน…
-
NLTK corpus readers for NECTEC BEST and ORCHID corpora
ความเดิมจากตอนที่แล้ว ทดลองสร้าง corpus reader ใน NLTK ตอนนี้แก้การ encode ให้ใช้ได้กับ nltk.Text() แล้ว (แทนที่จะเก็บเป็น unicode ก็เก็บเป็น utf-8 encoded str แทน) พร้อมกับเพิ่มตัวอ่านสำหรับคลังข้อความ BEST และ ORCHID ด้วย ตัวอ่านคลัง BEST ในรุ่น 0.3 นี้ เรียกดูเป็นหมวดได้ (ข่าว วรรณกรรม สารานุกรม บทความ) เรียกดูข้อมูลกำกับขอบเขตคำ (word boundaries) ได้ แต่ยังไม่รองรับ <NE>named-entities</NE> กับ <AB>คำย่อ</AB> เนื่องจาก BEST ไม่มีข้อมูลขอบเขตประโยค ตัวอ่านคลังจะสร้างขึ้นเอง โดยสมมติ \n เป็นขอบเขตประโยค ส่วนตัวอ่านคลัง ORCHID ในรุ่น 0.3 นี้ เรียกดูข้อมูลกำกับขอบเขตคำและชนิดคำ (Part-of-Speech)…
-
playing around Thai blog corpus with NLTK
อยากจะลองเล่น NLTK กับข้อมูลภาษาไทยดู คิดไปคิดมา เอาข้อมูลจาก foosci.com มาลองดูละกัน เขาเปิดให้ใช้ เป็น ครีเอทีฟคอมมอนส์ แสดงที่มา-อนุญาตแบบเดียวกัน (CC by-sa) แต่ไม่อยากไปดึงมาเอง ขี้เกียจ เห็นว่าโครงการโรตี (อัลฟ่า) โดย Opendream ดูดบล็อกไทยจำนวนหนึ่งมาเก็บไว้ได้ระยะหนึ่งแล้ว เพื่อใช้ในการแนะนำลิงก์ (ดูตัวอย่างที่ keng.ws ที่ท้ายแต่ละโพสต์) ก็เลยเอาจากตรงนั้นมาใช้ละกัน ข้อมูลที่มีเป็น XML ที่ dump มาจาก MySQL เราก็เขียนสคริปต์ก๊อก ๆ แก๊ก ๆ ดึงเฉพาะที่อยากได้ออกมา ด้วย xml.etree.cElementTree (ตอนแรกใช้ ElementTree แตน ๆ แต่อืดเกิน เนื่องจากแฟ้มมันใหญ่) เอา HTML tags ออกด้วย Beautiful Soup แล้วตัดคำด้วย python-libthai ตัดประโยคแบบถึก ๆ ด้วย…
-
encode("UTF-8", "ignore") ข้าม ๆ เรื่องที่ทำไม่ได้ใน Python
หลังจากเอา python-libthai ของวีร์มาใช้กับข้อมูลที่ได้มาจากเว็บ ก็พบปัญหาเรื่อง character encoding นิดหน่อย libthai นั้นปัจจุบันทำงานกับข้อมูลที่เป็นภาษาไทย 8 บิตอยู่ (น่าจะเป็น TIS-620) ตัว python-libthai เลยมีขั้นตอนการแปลงจากยูนิโค้ดไปเป็น 8 บิตก่อน ทีนี้ ปรากฏว่า encoder “CP874”, “TIS_620” และ “ISO8859_11” ของ Python มันดันแปลงตัวอักษรบางตัวไม่ได้ (เนื่องจากใน charset พวกนั้น มันไม่มีตัวอักษรดังกล่าว) โปรแกรมก็เลยจะตาย ถ้าไปเจออักษรพวกนั้น ก่อนตายมันจะโวยทำนองว่า : UnicodeEncodeError: ‘charmap’ codec can’t encode character u’\u200b’ in position 3560: character maps to <undefined> วิธีแก้แบบถึก ๆ คือ เอาหูไปนาเอาตาไปไร่ซะ ignore…
-
MSDN blogs on Nat Lang and Search
ทีมวิจัยพัฒนาของไมโครซอฟท์ ที่ทำด้านภาษาธรรมชาติในโปรแกรมออฟฟิศ และเครื่องมือค้นหาระดับองค์กร Microsoft Office Natural Language Team Blog คุณสมบัติที่เกี่ยวข้องในชุดออฟฟิศ ก็จะเป็นพวก ตัดคำ ใส่ยัติภังค์ (hyphenation) ตรวจและแนะนำตัวสะกด ตรวจและแนะนำไวยากรณ์ แปลภาษาอัตโนมัติ ย่อความอัตโนมัติ ค้นหาคำ Microsoft Enterprise Search Blog จะเป็นพวกคุณสมบัติการค้นหา ในโปรแกรมฝั่งเซิร์ฟเวอร์ เช่น Search Server, Office SharePoint, Windows SharePoint, Exchange Server, SQL Server รวมไปถึงการทำงานร่วมกับโปรแกรมของบริษัทอื่นด้วย เช่น Lotus Notes หรือการนำคอมโพเนนท์ที่เกี่ยวข้องของไมโครซอฟท์เอง มาให้บริการในสภาพการทำงานแบบองค์กร เช่น การนำเอา Virtual Earth Interactive Maps มาใช้ ใครสนใจก็ตามอ่านกันได้ครับ บานเลย – -“ โพสต์ที่น่าสนใจ เช่น…
-
swath 0.3.4 Released
โปรแกรมตัดคำ swath ออกรุ่น 0.3.4 แล้ว Swath 0.3.4 released. Swath (Smart Word Analysis for THai) is a word segmentation for Thai. Swath offers 3 algorithms: Longest Matching, Maximal Matching and Part-of-Speech Bigram. The program supports various file input format such as html, rtf, LaTeX as well as plain text. Changes from 0.3.1 (the most recent version…
-
Papers Written by Googlers
Research papers by people at Google including ones by Peter Norvig, Dominic Widdows, Marius Pasca … and of course Sergey Brin and Lawrence Page themselves ! ผลงานวิจัยตีพิมพ์จากกูเกิล คนพวกนี้เขาขยันคิดอะไรกันออกมาทุกวัน ? Peter Norvig นั่นเป็นเจ้าพ่อ AI เขียนหนังสือ Artificial Intelligence: A Modern Approach (ร่วมกับ Stuart Russell) น่าจะเป็นหนังสือ AI ที่ใช้ในชั้นเรียนมากที่สุด Dominic Widdows เขียนหนังสือที่ผมชอบมากเล่มนึง คือ Geometry and Meaning เราจะแทน/วัด “ความหมาย” ด้วยเรขาคณิตได้ไหม…
-
The 3rd ADD Summer School
The 3rd Asian Applied Natural Language Processing for Linguistics Diversity and Language Resource Development (ADD 3) Lectures + Workshops Feb 25 – Mar 3, 2008 @ Sirindhorn International Institute of Technology, Bangkadi Campus, Pathumthani, Thailand ปีนี้เน้นเรื่องการประมวลผลภาพ (ข้อความ) และการประมวลผลเสียงพูด พรุ่งนี้ว่าจะไปเข้าชั้นเรียน เรื่อง Semantic Web โดย อ.วิลาศ วูวงศ์ technorati tags: workshop, summer school, natural language processing