-
Google เปิดเผยข้อมูลการเซ็นเซอร์ละเอียดขึ้น
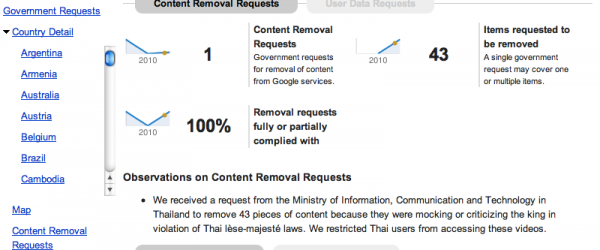
กูเกิลเปิดให้ใช้บริการ “รายงานความโปร่งใส” (Transparency Report) มาตั้งแต่ปีที่แล้ว และเมื่อวาน (27 มิ.ย. 2554) ก็ได้ประกาศปรับปรุงหน้าตาใหม่ พร้อมกับข้อมูลที่ละเอียดขึ้น Transparency Report ดังกล่าวประกอบไปด้วย 2 ส่วนหลัก คือ 1) การจราจร (Traffic) และ 2) คำร้องจากรัฐบาล (Government Requests) โดย Traffic จะแสดงปริมาณการจราจรที่เข้ามายังบริการต่าง ๆ ของกูเกิล ในแต่ละช่วงเวลา ซึ่งเมื่อดูในภาพรวมแล้ว จะทำให้เห็นได้ว่า เกิดเหตุผิดปกติอะไรกับการใช้อินเทอร์เน็ตในประเทศหนึ่ง ๆ หรือเปล่า เช่น ถ้าอยู่ดี ๆ ปริมาณการจราจรจากประเทศหนึ่งแทบจะหายไปเลย ก็พอจะบอกได้ว่า ไม่ 1) บริการของกูเกิลถูกแบนในประเทศดังกล่าว ก็ 2) อินเทอร์เน็ตของประเทศนั้นมีปัญหาอะไรสักอย่าง เช่น ช่องสัญญานออกนอกประเทศอาจจะขาด หรือบางทีอาจจะถูกตัดอย่างตั้งใจ (เช่นกรณีซีเรียหรือพม่า) ส่วน Government Requests จะบอกจำนวนคำร้องและเหตุผลที่ส่งมาจากรัฐบาลประเทศต่าง…
-
เปิดข้อมูลอย่างเดียวไม่พอ ต้องให้มัน machine-readable ด้วย!
สองสัปดาห์ก่อน พยายามจะเอาข้อมูลรายจ่ายภาครัฐมาใช้งาน แต่ก็พบปัญหาในการเอามาใช้ คือข้อมูลเท่าที่หาได้ มันไม่ machine-readable หรือ “อ่านด้วยเครื่องไม่ได้” เขียนสรุปเอาไว้ที่บล็อกโอเพ่นดรีม: รายจ่ายภาครัฐ ประจำปีงบประมาณ 2544-2554 ในรูปแบบ machine-readable (ดาวน์โหลดข้อมูลในฟอร์แมต OpenDocument) สาเหตุหลัก ๆ คือ: เป็น PDF ไม่ใช่ CSV หรือข้อมูลในรูปแบบตารางที่คำนวณได้ อย่าง OpenDocument spreadsheet หรือ Excel แย่กว่านั้น บาง PDF เป็นแบบรูปภาพ-สแกนหน้ากระดาษามา แถมเอียงหรือไม่ชัดอีกต่างหาก PDF ที่เหมือนจะเป็นข้อความดี ๆ บางอันก็มีปัญหาการเข้ารหัสชุดตัวอักษร เช่นแสดงให้เห็นเป็น “๔๕,๐๐๐,๐๐๐,๐๐๐” แต่พอ copy มา paste ก็กลายเป็น “Ùı,,,” แบบนี้คือ human-readable แต่ไม่ machine-readable แบบชัด ๆ เลย เอกสารใช้เลขไทย ซึ่งไม่ใช่ว่าทุก…
-
Thailand Open Data Catalog บัญชีข้อมูลเปิดของไทย
Open Data Thailand เป็นสมุดทะเบียนสำหรับชุดข้อมูลและเนื้อหาแบบเปิด เว็บไซต์นี้ทำงานด้วยซอฟต์แวร์ CKAN ซึ่งทำให้การค้นหา แบ่งปัน และใช้ข้อมูลซ้ำ ไปเป็นได้โดยง่าย โดยเฉพาะการทำงานเหล่านั้นด้วยวิธีการอัตโนมัติด้วยคอมพิวเตอร์ Open Data Thailand is an open registry of data and content packages. Harnessing the CKAN software, this site makes it easy to find, share and reuse content and data, especially in ways that are machine automatable. ไอเดียของ Open Data Catalog คือ พยายามรวบรวมข้อมูลสาธารณะและข้อมูลภาครัฐ ที่เปิดเผยอยู่แล้วในอินเทอร์เน็ต แต่อาจจะกระจัดกระจายอยู่…
-
สัมภาษณ์ @klaikong เรื่อง “ข้อมูลเปิดภาคสาธารณะ” กับการพัฒนาเศรษฐกิจ-สังคม-การเมือง #opendata #opengov
ผมสัมภาษณ์ พี่แต๊ก ไกลก้อง ไวทยการ (@klaikong) เอาไว้เมื่อวันที่ 4 ธ.ค. 2553 ที่ผ่านมา ระหว่างเวิร์กช็อป “Open Data Hackathon” ที่ Opendream คุยกันเรื่องความเคลื่อนไหว “ข้อมูลเปิดภาครัฐ” หรือ “ข้อมูลเปิดภาคสาธารณะ” (Open Government Data หรือ Open Public Data) กับความจำเป็นของสังคมไทยที่ภาครัฐจะต้องเปิดเผยข้อมูลให้สาธารณะเข้าถึงได้ เพื่อให้ทุกภาคส่วนสามารถร่วมพัฒนาประเทศไปพร้อม ๆ กัน ด้วยการตัดสินใจบนข้อมูลที่รอบด้าน ในสถานการณ์โลกที่เปลี่ยนแปลงไปอย่างรวดเร็ว วันนี้เพิ่งถอดเทปเสร็จ มีคุยกันเรื่องรูปแบบข้อมูล รวมถึงความเป็นไปได้ในการจะออกกฎระเบียบที่เกี่ยวข้อง : เรื่องมาตรฐานข้อมูลเนี่ย ประเทศเราทำไม่ได้จริงซะที คุยกันมานานแล้ว ว่าจะต้องมีระบบมาตรฐาน จะต้องมี standard อะไรต่าง ๆ XML ฯลฯ แต่ถึงทุกวันนี้ เท่าที่เห็น ร้อยละ 80 ข้อมูลก็ยังอยู่ในรูปแบบ PDF ซึ่งอันนี้มันสะท้อนเรื่องวิธีคิดว่า ข้อมูลนี้ก็ยังเป็นข้อมูลของหน่วยงานนั้นอยู่…
-
วารสารศาสตร์ข้อมูล: เราควรจะขอบคุณวิกิลีกส์ #wikileaks #opendata
ความน่าเชื่อถือของวิชาชีพนักข่าวนักหนังสือพิมพ์ วิกิลีกส์ และ วารสารศาสตร์ข้อมูล Roy Greenslade (twitter: @GreensladeR) เขียน ; อาทิตย์ สุริยะวงศ์กุล (@bact) แปลและเรียบเรียง (CNN) 30 ก.ค. 2553 – การโพสต์เอกสาร 92,000 ฉบับบนวิกิลีกส์ (WikiLeaks) เกี่ยวกับสงครามในอัฟกานิสถาน เป็นตัวแทนของการฉลองชัยของสิ่งที่ผมเรียกว่า “วารสารศาสตร์ข้อมูล” (data journalism) แน่นอนว่ามันต้องมีแหล่งข่าวที่เป็นบุคคล ใครสักคนในที่ไหนสักแห่ง ส่งต่อข้อมูลเหล่านี้ไปยังเว็บไซต์วิกิลีกส์ แต่ไม่ว่าผู้แจ้งความไม่ชอบมาพากลคนนี้จะเป็นใคร มันก็ไม่ได้สำคัญเท่ากับว่า เนื้อหาของเอกสารเหล่านี้มันบอกอะไรกับเรา ข้อมูลดิบดังกล่าว เป็นขุมทรัพย์ขนาดใหญ่สำหรับนักหนังสือพิมพ์ในสามสำนักข่าว – นิวยอร์กไทมส์ (New York Times สหัรฐอเมริกา), เดอะการ์เดียน (The Guardian สหราชอาณาจักร), และ แดร์สปีเกล (Der Spiegel เยอรมนี) – ที่จะขุดค้นหาข่าวจากมัน อย่างไรก็ตาม ไม่ได้มีเฉพาะนักข่าวเหล่านั้นเท่านั้น…